Machine Learning Appetizer Course
Session3: Recommendation Systems
Yu Yuen
Hern


Hongyi(Lance) Cai
Attendance QR code

An example
# Idealized Representation of Embedding
books = ["War and Peace", "Anna Karenina",
"The Hitchhiker's Guide to the Galaxy"]
books_encoded_ideal = [[0.53, 0.85],
[0.60, 0.80],
[-0.78, -0.62]]
...
An example
# Idealized Representation of Embedding
books = ["War and Peace", "Anna Karenina",
"The Hitchhiker's Guide to the Galaxy"]
books_encoded_ideal = [[0.53, 0.85],
[0.60, 0.80],
[-0.78, -0.62]]
Similarity (dot product) between First and Second = 0.99
Similarity (dot product) between Second and Third = -0.94
Similarity (dot product) between First and Third = -0.97

Answer
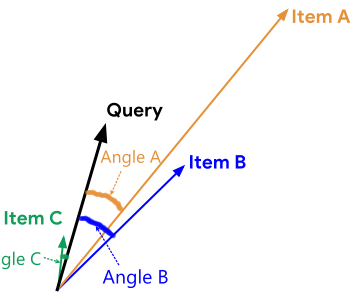
Cosine Answer : C-A-B
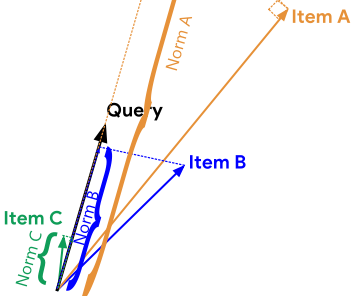
Dot Answer(Norm) : A-B-C
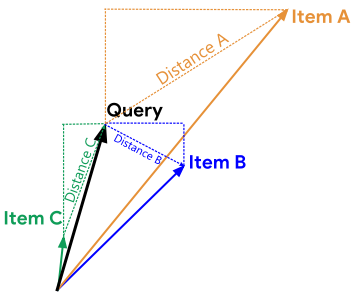
Eculidean Distance : C-B-A

Collaborative Filtering
Collaborative filtering uses similarities between users and items simultaneously to provide recommendations. Hence collaborative filtering can recommend an item to user A based on the interests of similar user B.
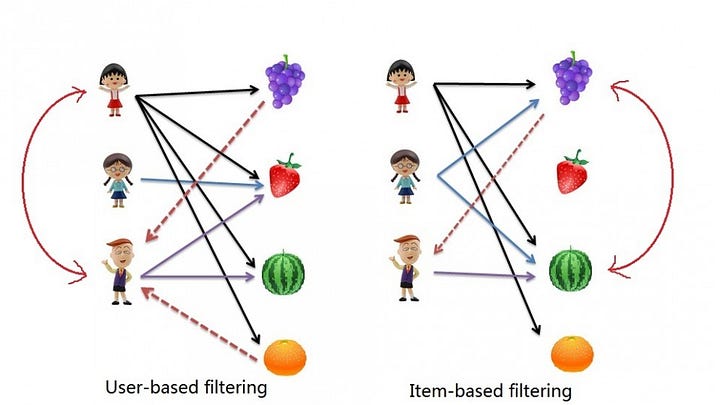
From the figure above, notice that there are two types of collaborative filtering: user-based and item-based. Let's look at user-based first.

THE END
